
Tidytext makes it so much easier
Recently I have been watching Tidytuesday screencast from David Robinson. In his screencast he selects never seen before dataset and analyses it using R. Today I’m going to follow in his footsetp. In this blog post I’m going to analyse a set of data and visualize the result using ggplot2. The dataset is collected from medium.com. I’m going to breakdown all the titles of the articles into indivisual words and try to see which word is used the most in all of them.
Read in data
medium_datasci <- read_csv("medium_datasci.csv")Cleaning data
The dataset contains the first column as x1 which we don’t need so lets deselect it and save the dataframe as medium_processed.
medium_processed<- medium_datasci %>%
select(-x1)There is a handy function called summarise_at which can be used as
medium_processed %>%
summarise_at(vars(starts_with("tag_")),sum)## # A tibble: 1 x 8
## tag_ai tag_artificial_~ tag_big_data tag_data tag_data_science
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 13763 29580 8686 9420 15424
## # ... with 3 more variables: tag_data_visualization <dbl>,
## # tag_deep_learning <dbl>, tag_machine_learning <dbl>It summarises only those columns which starts with tag_ and the summarise function is sum in this case.
More data processing
medium_processed %>%
select(starts_with("tag"))## # A tibble: 78,388 x 8
## tag_ai tag_artificial_~ tag_big_data tag_data tag_data_science
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 0 0 0 0
## 2 1 0 0 0 0
## 3 1 0 0 0 0
## 4 1 0 0 0 0
## 5 1 0 0 0 0
## 6 1 0 0 0 0
## 7 1 0 0 0 0
## 8 1 0 0 0 0
## 9 1 0 0 0 0
## 10 1 0 0 0 0
## # ... with 78,378 more rows, and 3 more variables:
## # tag_data_visualization <dbl>, tag_deep_learning <dbl>,
## # tag_machine_learning <dbl>We can see value 1 or 0 is assigned to indicate whether certain tag like ai or big_data appear in the article. This gives us a good opportunity to gather the data. It gathers all those columns which starts with tag into 2 columns called tag and value.
medium_gathered<- medium_processed %>%
gather(tag,value,starts_with("tag"))
medium_gathered## # A tibble: 627,104 x 14
## title subtitle image author publication year month day reading_time
## <chr> <chr> <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Onli~ Online ~ 1 Emma ~ <NA> 2017 8 1 5
## 2 A.I.~ <NA> 0 Sanpa~ <NA> 2017 8 1 2
## 3 Futu~ From Ph~ 1 Z <NA> 2017 8 1 3
## 4 The ~ A true ~ 1 Emiko~ MILLENNIAL~ 2017 8 1 5
## 5 Os M~ mas per~ 1 Giova~ NEW ORDER 2017 8 1 3
## 6 The ~ Origina~ 1 Syed ~ Towards Da~ 2017 8 1 6
## 7 Digi~ Health ~ 1 Anna ~ <NA> 2017 8 1 5
## 8 Addr~ https:/~ 0 The A~ <NA> 2017 8 1 0
## 9 Wir ~ <NA> 1 Angel~ <NA> 2017 8 1 4
## 10 <NA> 199973 0 The p~ <NA> 2017 8 1 3
## # ... with 627,094 more rows, and 5 more variables: claps <dbl>,
## # url <chr>, author_url <chr>, tag <chr>, value <dbl>We don’t need"tag_ so can be removed and filter out only value 1 which indicate the tag exists.
medium_filter<-medium_gathered %>%
mutate(tag = str_remove(tag,"tag_")) %>%
filter(value ==1)## Warning: package 'bindrcpp' was built under R version 3.5.2medium_filter## # A tibble: 112,994 x 14
## title subtitle image author publication year month day reading_time
## <chr> <chr> <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Onli~ Online ~ 1 Emma ~ <NA> 2017 8 1 5
## 2 A.I.~ <NA> 0 Sanpa~ <NA> 2017 8 1 2
## 3 Futu~ From Ph~ 1 Z <NA> 2017 8 1 3
## 4 The ~ A true ~ 1 Emiko~ MILLENNIAL~ 2017 8 1 5
## 5 Os M~ mas per~ 1 Giova~ NEW ORDER 2017 8 1 3
## 6 The ~ Origina~ 1 Syed ~ Towards Da~ 2017 8 1 6
## 7 Digi~ Health ~ 1 Anna ~ <NA> 2017 8 1 5
## 8 Addr~ https:/~ 0 The A~ <NA> 2017 8 1 0
## 9 Wir ~ <NA> 1 Angel~ <NA> 2017 8 1 4
## 10 <NA> 199973 0 The p~ <NA> 2017 8 1 3
## # ... with 112,984 more rows, and 5 more variables: claps <dbl>,
## # url <chr>, author_url <chr>, tag <chr>, value <dbl>Here if you see, the data is organised into tidy format row-wise. It seems all good but we can’t do nothing with a sentence (title), unless we break sentences into words and arrange them row-wise again. Here comes the magic of tidytext.
medium_words<-medium_filter %>%
unnest_tokens(word,title)
medium_words## # A tibble: 841,539 x 14
## subtitle image author publication year month day reading_time claps
## <chr> <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Online ~ 1 Emma ~ <NA> 2017 8 1 5 12
## 2 Online ~ 1 Emma ~ <NA> 2017 8 1 5 12
## 3 Online ~ 1 Emma ~ <NA> 2017 8 1 5 12
## 4 Online ~ 1 Emma ~ <NA> 2017 8 1 5 12
## 5 Online ~ 1 Emma ~ <NA> 2017 8 1 5 12
## 6 Online ~ 1 Emma ~ <NA> 2017 8 1 5 12
## 7 <NA> 0 Sanpa~ <NA> 2017 8 1 2 11
## 8 From Ph~ 1 Z <NA> 2017 8 1 3 1
## 9 From Ph~ 1 Z <NA> 2017 8 1 3 1
## 10 From Ph~ 1 Z <NA> 2017 8 1 3 1
## # ... with 841,529 more rows, and 5 more variables: url <chr>,
## # author_url <chr>, tag <chr>, value <dbl>, word <chr>Each sentence is broken into words and arranged into each row. If we want to see what word appears the most, we can use handy count function with sort = TRUE
Polish the result
medium_words %>%
count(word, sort = TRUE)## # A tibble: 44,259 x 2
## word n
## <chr> <int>
## 1 the 27555
## 2 to 19378
## 3 data 18856
## 4 of 16417
## 5 and 16327
## 6 in 15526
## 7 ai 15163
## 8 learning 13735
## 9 a 13463
## 10 for 11374
## # ... with 44,249 more rowsBut as you can see there are lots of words like ‘the’, ‘a’,‘in’. These are called stop words and we have to filter them out. Fot that we use ‘anti_join’ with tidytext’s built in stop_words dataset. We need to filter out numbers and few other words as a clean up step.
medium_words_sort<-medium_words %>%
anti_join(stop_words) %>%
filter(word != "de",
str_detect(word,"[a-z]")) %>%
count(word, sort = TRUE)
medium_words_sort## # A tibble: 42,727 x 2
## word n
## <chr> <int>
## 1 data 18856
## 2 ai 15163
## 3 learning 13735
## 4 machine 8732
## 5 intelligence 6441
## 6 artificial 6306
## 7 deep 4832
## 8 science 3837
## 9 future 2574
## 10 neural 2298
## # ... with 42,717 more rowsPlot the result
Our result shows the word ‘data’ is the hightest, followed by the word ‘ai’. We are almost done but what good if we can’t see the result visually. so now comes the fun part. Lets pick up top 10 and try to plot out findings.
medium_words_sort %>%
head(10) %>%
mutate(word = fct_reorder(word,n)) %>%
ggplot(aes(word,n,fill = word))+
geom_col(show.legend = FALSE)+
coord_flip()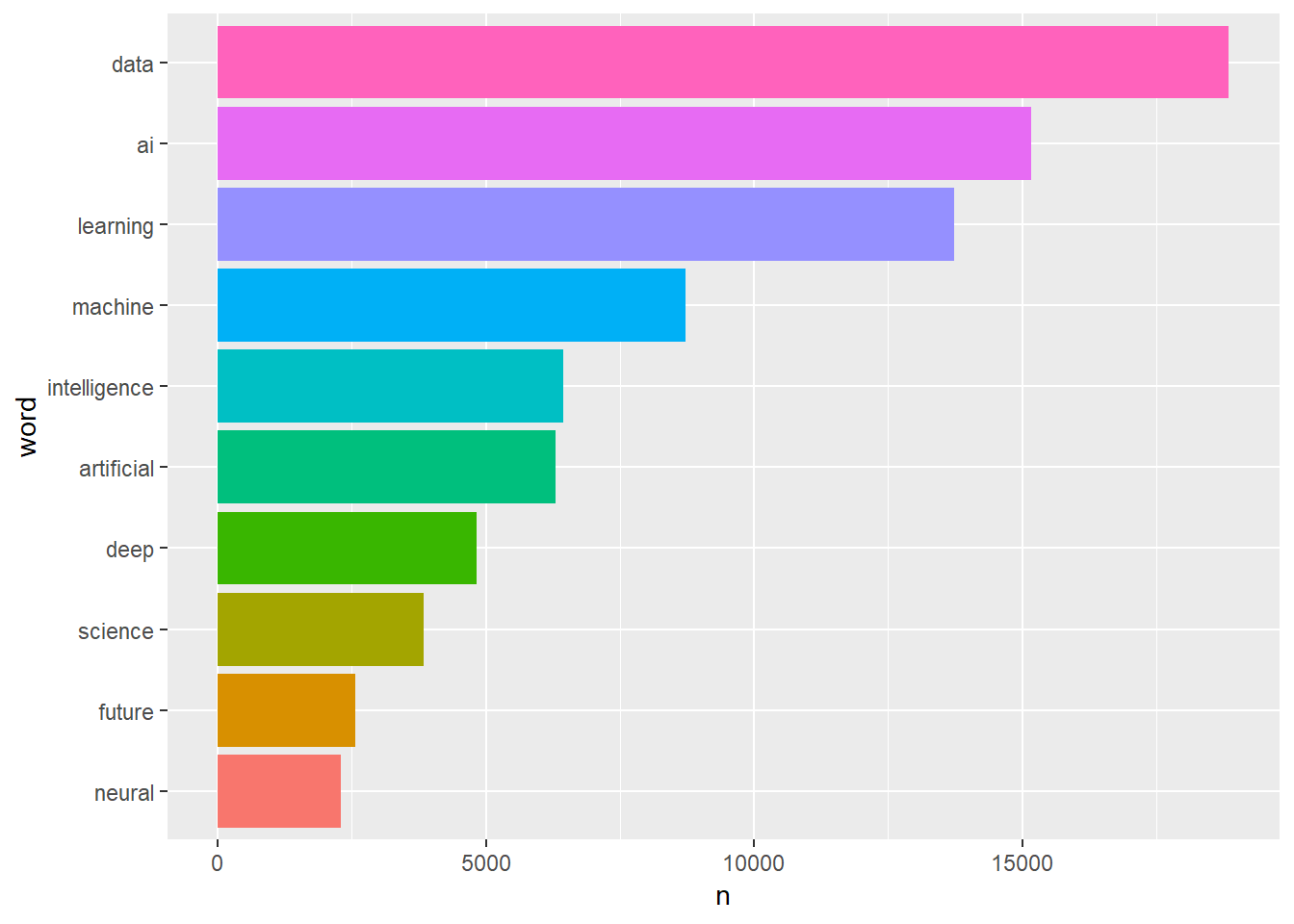 we used
we used fct_reorder so words are arranged by the order of their count (n).
Conclusion
In few steps how we are able to analyse the data and quickly visualize the result. I love how tidytext simplified the complex procedure and helped to produce the output elegantly. If you want to know more please visit Tidytuesday project and ofcourse out of all for the best screencast visit David Robinson’s screencast.
